Presentación.
Modelos no Paramétricos y de Regresión
Gonzalo Pérez
27 de enero de 2020
Características generales del curso
Profesor: Gonzalo Pérez (cubículo 212, Departamento de Matemáticas, gonzalo.perez@ciencias.unam.mx).
Ayudante: Dioney Alonso Rosas (dioney@ciencias.unam.mx).
Horario: lunes a viernes de 17 a 18 hrs.
Salón: P101
Evaluación
Cinco examenes parciales, dos de ellos son tarea-examen. Cada examen tiene un valor de 20% de la calificación.
Cada examen es antecedido por una tarea. Las tareas se entregarán de forma opcional. Se podrán entregar por parejas y SÓLO con calificación mayor o igual a 9 tendrán un valor de un punto adicional al examen parcial correspondiente.
Como parte de cada tarea-examen, el alumno deberá entregar un reporte escrito y realizar una presentación de los resultados al grupo, así como una breve descripción de los paquetes estadísticos usados. La tarea-examen se realizará en equipos, el número de integrantes se definirá de acuerdo con el número de alumnos inscritos.
Notas sobre la evaluación
Se podrá reponer sólo un examen parcial renunciando a la calificación previa obtenida.
Habrá un exámen final que podrá presentarse de forma opcional renunciando a la calificación final previamente obtenida.
La calificación se redondea al entero más cercano a partir de 6, de otra forma la calificación es no aprobatoria.
Se califica con NP en actas únicamente cuando el número de exámenes presentados es menor a 2.
Temas por cubrir en el curso.
- Estadística No Paramétrica
Pruebas de Bondad de Ajuste
¿Se puede asumir que la muestra proviene de una cierta distribución?
Pruebas de aleatoriedad.
¿Se puede asumir que los datos observados son aleatorios?
Pruebas sobre la igualdad de una o más poblaciones
¿Se puede asumir que dos poblaciones tienen la misma distribución?
Medidas de asociación
¿Existe una asociación entre pares de variables (numéricas, ordinales)?
- Análisis de regresión lineal simple y múltiple
¿De qué trata el tema de regresión lineal simple?
Tenemos acceso a un conjunto de \(n\) observaciones
\[z_1, ..., z_n.\]
Cada observación es un vector de dos variables, es decir,
\(z_i=(y_i, x_i), i=1,...,n\).
Por ejemplo. Supongamos que se tiene acceso a un conjunto de 32 datos medidos en automóviles; en donde \(y_i\) corresponde a las millas por galón que recorre el auto \(i-ésimo\) y \(x_i\) a su peso. Supongamos que queremos comprar un auto, pero quisieramos saber si es posible reducir costos en gasolina a partir de las características del automóvil. Algunas preguntas que se pueden derivar de estos datos son:
- ¿A mayor peso del auto se gasta más gasolina? ¿En qué magnitud?
- ¿La relacion entre el peso del auto y el gasto de gasolina es lineal?
Veamos qué nos dicen los datos!
str(mtcars)## 'data.frame': 32 obs. of 11 variables:
## $ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...
## $ cyl : num 6 6 4 6 8 6 8 4 4 6 ...
## $ disp: num 160 160 108 258 360 ...
## $ hp : num 110 110 93 110 175 105 245 62 95 123 ...
## $ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...
## $ wt : num 2.62 2.88 2.32 3.21 3.44 ...
## $ qsec: num 16.5 17 18.6 19.4 17 ...
## $ vs : num 0 0 1 1 0 1 0 1 1 1 ...
## $ am : num 1 1 1 0 0 0 0 0 0 0 ...
## $ gear: num 4 4 4 3 3 3 3 4 4 4 ...
## $ carb: num 4 4 1 1 2 1 4 2 2 4 ...require(ggplot2)
require(ggiraph)
require(ggiraphExtra)
ggPoints(aes(x=wt,y=mpg),data=mtcars,method="lm",interactive=TRUE)La linea azul corresponde a una recta parametrizada como
\[Y=\beta_1+\beta_2 X\]
Preguntas a resolver durante el curso:
- ¿Cómo estimar los parámetros de la regresión lineal, \(\beta_1, \beta_2\)?
- ¿Cómo verificar que realmente a mayor peso mayor gasto de gasolina?
- ¿Cómo interpretar los parámetros? ¿Qué propiedades tienen?
En general se puede observar lo siguiente en cuanto a la interpretación de la recta:
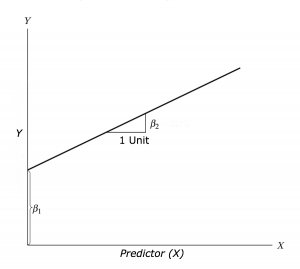
¿Qué herramientas computacionales podemos usar?
Python
Sólo se mostrarán funciones básicas.
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
model = smf.ols('mpg ~ wt', data = r.mtcars).fit()
print(model.summary())## OLS Regression Results
## ==============================================================================
## Dep. Variable: mpg R-squared: 0.753
## Model: OLS Adj. R-squared: 0.745
## Method: Least Squares F-statistic: 91.38
## Date: Wed, 16 Sep 2020 Prob (F-statistic): 1.29e-10
## Time: 23:17:53 Log-Likelihood: -80.015
## No. Observations: 32 AIC: 164.0
## Df Residuals: 30 BIC: 167.0
## Df Model: 1
## Covariance Type: nonrobust
## ==============================================================================
## coef std err t P>|t| [0.025 0.975]
## ------------------------------------------------------------------------------
## Intercept 37.2851 1.878 19.858 0.000 33.450 41.120
## wt -5.3445 0.559 -9.559 0.000 -6.486 -4.203
## ==============================================================================
## Omnibus: 2.988 Durbin-Watson: 1.252
## Prob(Omnibus): 0.225 Jarque-Bera (JB): 2.399
## Skew: 0.668 Prob(JB): 0.301
## Kurtosis: 2.877 Cond. No. 12.7
## ==============================================================================
##
## Warnings:
## [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.R
También se mostrarán sólo las funciones básicas y será lo prioritario durante las prácticas.
modelinR = lm('mpg ~ wt', data = mtcars)
print(summary(modelinR))##
## Call:
## lm(formula = "mpg ~ wt", data = mtcars)
##
## Residuals:
## Min 1Q Median 3Q Max
## -4.543 -2.365 -0.125 1.410 6.873
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 37.285 1.878 19.86 < 2e-16 ***
## wt -5.344 0.559 -9.56 1.3e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3 on 30 degrees of freedom
## Multiple R-squared: 0.753, Adjusted R-squared: 0.745
## F-statistic: 91.4 on 1 and 30 DF, p-value: 1.29e-10En cualquier caso, el objetivo principal es interpretar las salidas.
Regresión lineal múltiple
¿Se pueden incluir más variables para analizar el gasto de gasolina?
Por ejemplo, ¿se podría incluir la variable caballos de fuerza del automóvil (hp)?
pairs(mtcars[,c("mpg", "wt", "hp")])
Si se incluye una variable categórica, ¿cómo usarla? ¿cómo se interpreta?
Por ejemplo, si se conoce el tipo de transmisión del automóvil ¿se podría concluir que dada ésta la relación lineal es la misma?
ggPoints(aes(x=wt,y=mpg,color=am),data=mtcars,method="lm",interactive=TRUE)Bibliografía
- Agresti, A. (2015). Foundations of linear and generalized linear models. Wiley.
- Dobson, A. y Barnett, A. (2018). An introduction to generalized linear models. CRC Press.
- Fox, J. (2015) Applied Regression Analysis and Generalized Linear Models. Sage Publications, Thousand Oaks, California.
- Gibbons, J. D. y Chakraborti, S. (2011). Nonparametric statistical inference. CRC Press.
- Graybill, F. A. y Iyer, H. K. (1994). Regression Analysis: Concepts and Applications. Duxbury Press.
- Hollander M., Wolfe, D. y Chicken, E. (2014). Nonparametric Statistical Methods. Wiley.
- Kutner, M., Nachtsheim, C., Neter, J. y Li, W. (2005). Applied Linear Statistical Models. McGraw-Hill.
- Montgomery, D., Peck, E.A. y Vining, G.G. (2012). Introduction to Linear Regression Analysis. Wiley.
- Searle, S.R. (1971). Linear Models. Wiley.
- Seber, G.A.F. y Lee, A. (2003). Linear Regression Analysis. Wiley.
- Sheskin, D. (2011). Handbook of parametric and nonparametric statistical procedures. Chapman and Hall.
- Sprent, P. y Smeeton, N. (2007). Applied Nonparametric Statistical Methods. Chapman and Hall/CRC.
- Weisberg, S. (2014). Applied Linear Regression. John Wiley & Sons.