Análisis de regresión simple
Gonzalo Pérez, Graciela Martínez
13 de marzo de 2020
Tarea 1. Para ser entregada el 24 de marzo.
1.
Los \(ping\ddot{u}inos\) \(Macaroni\) ponen nidadas de dos huevos de tamaño diferente. El peso en gramos de los huevos de 11 nidadas se presenta en la tabla de abajo.
- Ajuste la recta de regresión del peso del huevo mayor en el peso del huevo menor. Comente sobre el ajuste del modelo.
- Pruebe si la pendiente de la regresión difiere significativamente (estadísticamente) de la unidad. Interprete.
- Posteriormente se observa el peso de los huevos de una nueva nidada, observándose un peso de 75 y 115 gramos. Usando un intervalo adecuado, comente sobre la sospecha de que la nidada de huevos no proviene de pinguinos \(Macaroni.\)
x=c(79, 93, 100, 105, 101, 96, 96, 109, 70, 71, 87)
y=c(133, 143, 164, 171, 165, 159, 162, 170, 127, 133, 148 )
Datos9=data.frame(cbind(x,y))
kable(Datos9)| x | y |
|---|---|
| 79 | 133 |
| 93 | 143 |
| 100 | 164 |
| 105 | 171 |
| 101 | 165 |
| 96 | 159 |
| 96 | 162 |
| 109 | 170 |
| 70 | 127 |
| 71 | 133 |
| 87 | 148 |
ggplot(data=Datos9, aes(x=x,y=y))+
geom_point(colour="black")+theme_classic()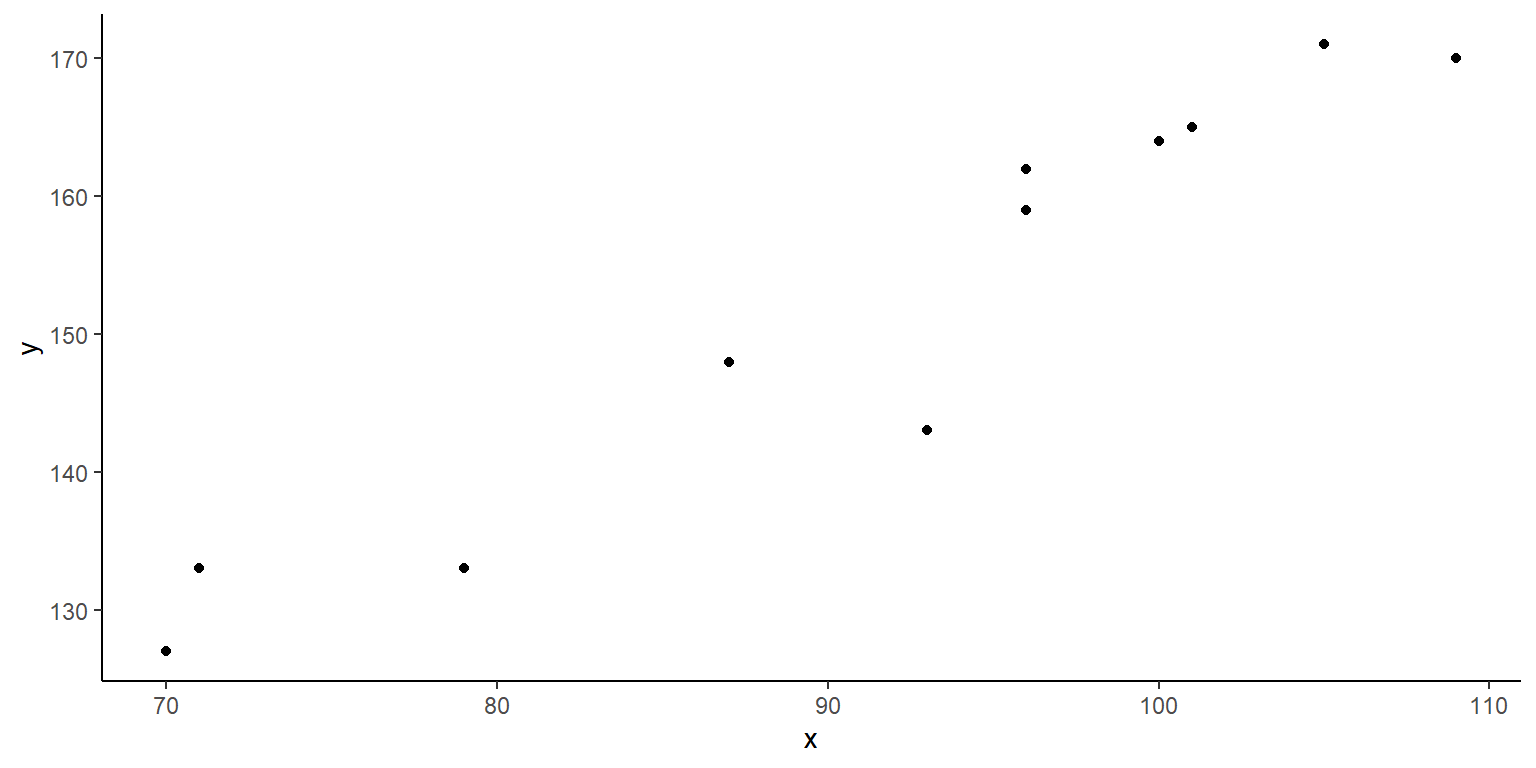
2.
En una gran universidad se seleccionó al azar a 7 estudiantes de economía y se les aplicó una encuesta. Dos de las preguntas fueron: (1) ¿Cuál es el porcentaje de GPA en el semestre anterior?, (2) En promedio ¿Cuántas horas a la semana pasó durante el último semestre en el bar X? El bar X es un lugar muy conocido por los estudiantes.
Est=c(1 , 2 , 3 , 4 , 5 , 6 , 7 )
G=c(3.6, 2.2, 3.1, 3.5, 2.7, 2.6, 3.9)
H=c(3, 15, 8, 9, 12, 12, 4)
Datos10=data.frame(cbind(Est,G,H))
Datos10ggplot(data=Datos10, aes(x=H,y=G))+
geom_point(colour="black")+theme_classic()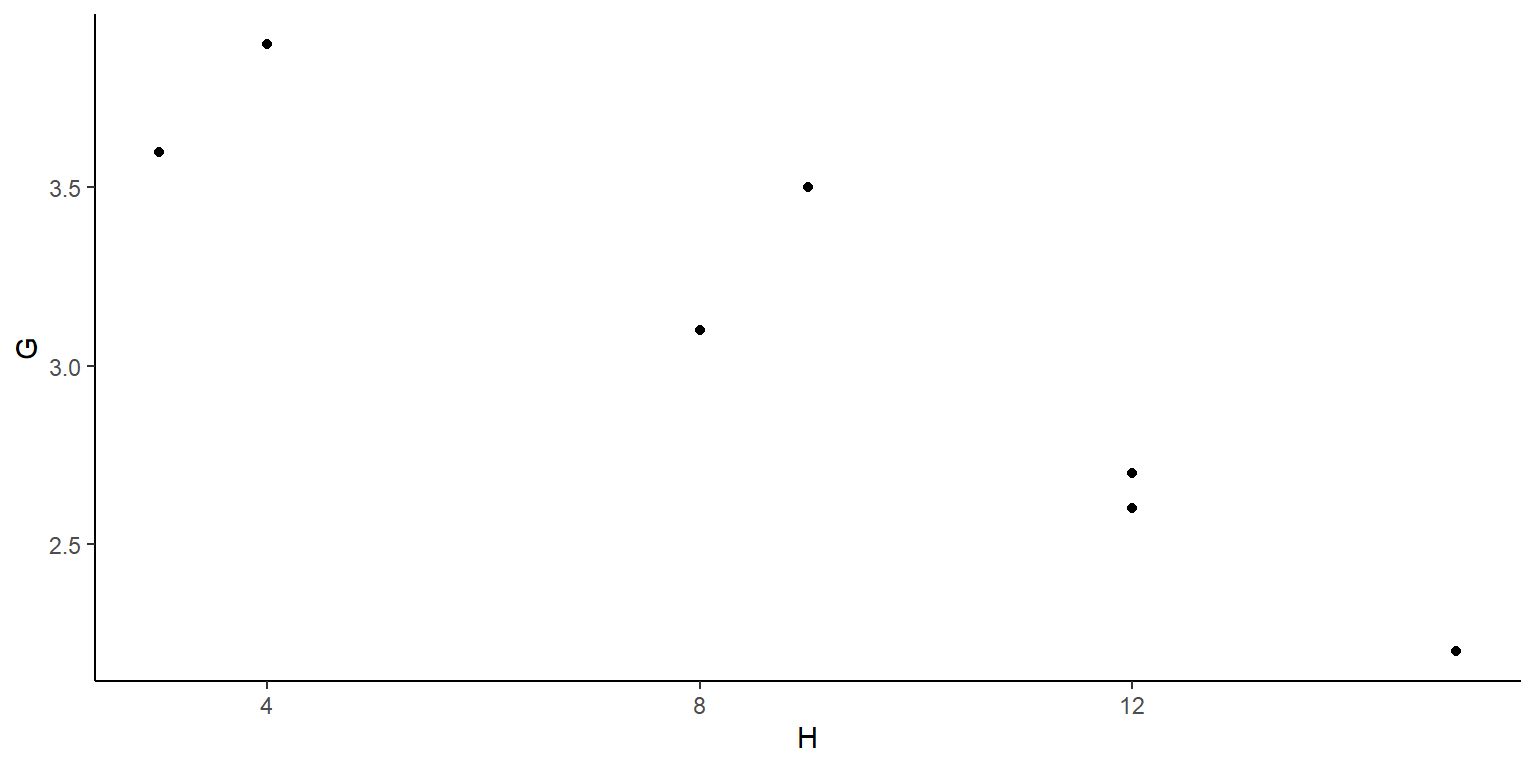
- ¿Dirías que un modelo lineal simple serviría para describir la relación entre G (puntaje del GPA) y H (horas a la semana en el bar)?
- Ajusta un modelo lineal simple
- Encuentra \(\hat{\sigma}^2\), las desviaciones estándar estimadas para \(\hat{\alpha}\) y \(\hat{\beta}\), sus intervalos de confianza y el \(R^2\). ¿Qué puedes decir al respecto?
- Realiza la prueba \(t\) para contrastar \(H_{0}: \beta=0 \quad vs \quad H_{a}:\beta \neq 0\). Comenta.
- Obtén la tabla ANOVA y realiza la prueba asociada con una significancia de .05.
- Suponga ahora que un nuevo estudiante de economía pasa 15 horas a la semana en el bar durante las dos primeras semanas de clase. Calcule un intervalo para su porcentaje de GPA en su primer semestre si continúa pasando 15 horas a la semana en el bar.
- ¿Cuál sería la variación promedio del porcentaje de GPA al aumentar en una hora a la semana la estancia en el bar? De un intervalo de confianza al \(90\%\)
- Suponga que un grupo de 5 estudiantes acudirá al bar en promedio 10 horas a la semana durante el siguiente semestre, ¿Cuál será el porcentaje de GPA promedio de los cinco estudiantes para el próximo semestre?. Calcule un intervalo.
- Describa en general cuál es el porcentaje de GPA promedio de los estudiantes que asisten 8 horas a la semana al bar.
- Suponga que al lado del bar X existe una cafeteria. Un analista supone que, en principio, el porcentaje promedio de GPA de los estudiantes que no acuden al bar es igual al porcentaje promedio de los que no acuden a la cafetería. Sin embargo, cree por su experiencia que el patrón observado en el cambio promedio del porcentaje de GPA al aumentar una hora de estancia en la cafetería es sólo de la mitad de la observada al aumentar una hora de estancia en el bar. Es decir, al analista le parece plausible usar un modelo de regresión del estilo: \[y_{i}=\alpha+\frac{\beta}{2} x_{i}^*+\epsilon\] Donde \(x^*\) es el promedio en horas a la semana que los estudiantes pasan en la cafetería durante un semestre y \(y\) el correspondiente porcentaje de GPA. Los demás parámetros asociados a este modelo son los mismos a los asociados al modelo original. Dado que no se cuentan con observaciones para este estudio particular y sólo se tiene el supuesto del analista, se deciden usar los estimadores \(\hat{\alpha}\) y \(\hat{\beta}\). Calcule un intervalo de confianza al \(95\%\) para el porcentaje de GPA promedio de los estudiantes que acuden 8 horas a la semana al cafetería.
3.
El objetivo de los siguientes datos es analizar si los gramos consumidos al día de fibra tienen una relación con el nivel de plasma beta-carotene. El interés original de estos datos fue recabar información que pudiera servir para encontrar los factores asociados con niveles bajos de plasma beta-carotene dado que estos podrían estar asociados con el riesgo de desarrollar algunos canceres.
Datos=read.table("images/archivos/prdata.dat",
header=FALSE, sep="\t")
names(Datos)=c("AGE", "SEX", "SMOKSTAT", "QUETELET", "VITUSE", "CALORIES", "FAT", "FIBER", "ALCOHOL", "CHOLESTEROL", "BETADIET", "RETDIET", "BETAPLASMA", "RETPLASMA")
head(Datos)str(Datos)## 'data.frame': 315 obs. of 14 variables:
## $ AGE : int 64 76 38 40 72 40 65 58 35 55 ...
## $ SEX : int 2 2 2 2 2 2 2 2 2 2 ...
## $ SMOKSTAT : int 2 1 2 2 1 2 1 1 1 2 ...
## $ QUETELET : num 21.5 23.9 20 25.1 21 ...
## $ VITUSE : int 1 1 2 3 1 3 2 1 3 3 ...
## $ CALORIES : num 1299 1032 2372 2450 1952 ...
## $ FAT : num 57 50.1 83.6 97.5 82.6 56 52 63.4 57.8 39.6 ...
## $ FIBER : num 6.3 15.8 19.1 26.5 16.2 9.6 28.7 10.9 20.3 15.5 ...
## $ ALCOHOL : num 0 0 14.1 0.5 0 1.3 0 0 0.6 0 ...
## $ CHOLESTEROL: num 170.3 75.8 257.9 332.6 170.8 ...
## $ BETADIET : int 1945 2653 6321 1061 2863 1729 5371 823 2895 3307 ...
## $ RETDIET : int 890 451 660 864 1209 1439 802 2571 944 493 ...
## $ BETAPLASMA : int 200 124 328 153 92 148 258 64 218 81 ...
## $ RETPLASMA : int 915 727 721 615 799 654 834 825 517 562 ...Ajuste una regresión con las variables BETAPLASMA y FIBER. Defina como debería establecerse el modelo de regresión. ¿Con base en el ajuste qué puede decir?
Realice un análisis de los residuales para verificar los supuestos del modelo ajustado en i). ¿Qué se puede concluir?
En caso de que algún supuesto no se cumpla u observe alguna observación que se pueda considerar influyente realice los ajustes necesarios y vuelva a ajustar un modelo de regresión.
En general, comente sobre el significado del coeficiente de determinación. ¿Qué nos está sugiriendo?
4.
Los datos Davis contienen las mediciones sobre peso y estatura tomadas a hombres y mujeres que realizan ejercicio regular. También contiene los valores de peso y altura que estos individuos dijeron tener antes de tomar las mediciones, es decir, el autoreporte.
library(carData)
Datos=Davis
head(Datos)str(Datos)## 'data.frame': 200 obs. of 5 variables:
## $ sex : Factor w/ 2 levels "F","M": 2 1 1 2 1 2 2 2 2 2 ...
## $ weight: int 77 58 53 68 59 76 76 69 71 65 ...
## $ height: int 182 161 161 177 157 170 167 186 178 171 ...
## $ repwt : int 77 51 54 70 59 76 77 73 71 64 ...
## $ repht : int 180 159 158 175 155 165 165 180 175 170 ...El objetivo de los investigadores es saber si el peso y altura reportados por los individuos es suficientemente preciso para reemplazar los valores reales (las mediciones).
Ajuste la regresión repwt sobre weight, incluya el análisis de residuales. Indique si se puede decir que lo que reportan los individuos sobre su peso está asociado al peso real o hay un sesgo.
Ajuste la regresión weight sobre repwt, incluya el análisis de residuales. Indique si se puede decir que lo que reportan los individuos sobre su peso está asociado al peso real o hay un sesgo.
Comente sobre los resultados y dé una única conclusión.